# 강의 영상
정리
이번 장에서는, 우리는 다시 total order broadcast 의 문제에 대해서 되돌아가보도록 하겠습니다. 바로 이전 장에서 우리는 state machine replication (SMR) 을 활성화 하는데 total order broadcast 가 굉장히 유용할 것이라는 것을 보았어요. 그리고, 이 total order broadcast 를 구현하는 방법중의 하나로 하나의 노드를 leader 로 만들고, 모든 메시지를 그 leader 를 통하도록 하는 방법도 살펴 보았습니다. leader 는 받은 메시지를 FIFO broadcast 로 각 노드들에 전달하게 되고, 이는 각 메시지들이 동일한 순서대로 전달 되는 것을 보장해줄 수 있습니다.
하지만, 이 구조의 가장 큰 그리고 중요한 문제점은 leader 가 바로 Single point of failure (SPOF) 가 될 수 있다는 점입니다. leader 가 갑자기 장애가 나는 경우에는 어떻게 해야 할까요? 이런 경우에 우리는 자동으로 다른 노드를 leader 로 설정될 수 있기를 바랄 것입니다. 그리고 이번 장에서 이 leader 가 자동으로 변경되는 알고리즘에 대해서 알아보도록 하겠습니다.
합의(Consensus)
합의란 무엇일까요. 합의에 대한 문제는 예전 부터 꾸준히 존재했던 주제입니다. 여러 노드들이 있을때, 각 노드들에서 나온 값 중에 어떤 값을 결정할 것인지를 이 합의 알고리즘을 통해서 결정하게 됩니다. 여기서 봐야할 점은, 합의 와 total-order broadcast 는 서로 동일한 개념이어서, 서로 대체될 수 있다는 점입니다.

잘 알려져 있는 합의 알고리즘으로는 Paxos 와 Raft 알고리즘이 있습니다. Paxos나 Raft 알고리즘은 fail-recover 시스템 모델 즉, 장애에의해 다운되고 복구되는 모델에 적합한 알고리즘입니다. 이러한 알고리즘들을 non-byzantine 시스템 모델이라고 합니다. 여기서 byzantine 문제는 앞서 본것 처럼 악의적인 공격이 생길 수 있는 상황을 말합니다. byzantine 문제를 해결하기 위한 합의 알고리즘은 보다 복잡하고, 그렇게 효율적이지 못합니다. (그리고 이 byzantine 문제를 해결한 합의 알고리즘이 비트코인의 PoW 방법이죠..)
대부분의 합의 알고리즘에서 중요하게 봐야하는 부분은 기존에 리더가 장애가 났을때 새로운 리더를 선정하기 위한 투표를 하는 방식입니다. 이 글에서는 Raft 알고리즘에서 사용한 리더 투표(leader election) 방식을 중점으로 설명하도록 하겠습니다. 리더 투표는 기존의 리더에게서 주기적으로 오던 메시지가 오지 않는 등의 리더가 정상적으로 동작하지 않고 있다고 판단될때 시작됩니다. 그러면서, 리더를 제외한 다른 노드들 중에 하나는 candidate 노드가 되고, 다른 노드들로 하여금 내가 새로운 리더 가 되어도 될지 투표를 시작합니다. 만약 노드들의 quorum 정도가 동의 한다면 cadidate 는 새로운 리더로 승격 됩니다.
이때 만약, 여러개의 리더가 존재하는 상황이 발생한다면, 데이터의 정합성에 문제가 생기기 때문에 리더 투표를 할 때 중요하게 봐야할 것중에 하나는 오직 한번에 하나의 리더만 승격될 수 있도록 하는 것입니다. Raft 알고리즘에서는 "한번에 하나"의 리더만 선출되도록 하기 위해 "term" 개념을 사용하여 해결하고 있습니다. "term" 은 리더 투표가 일어날 때 마다 +1 되는 정수 값입니다. 그렇게 해서 한 term 에는 하나의 리더만 선출 될 수 있도록 보장하게 됩니다.
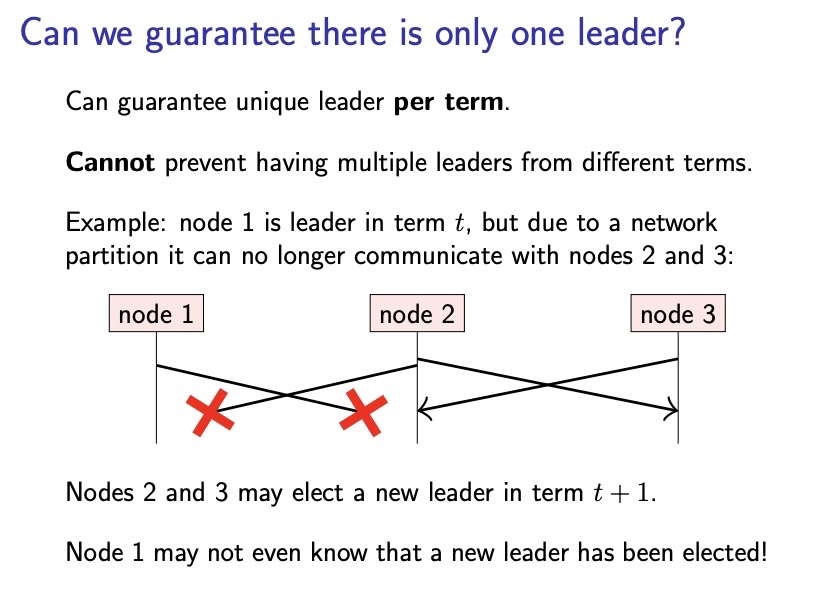
하지만 다음과 같은 상황에서는 어떻게 하나의 리더만 존재할 수 있다고 보장할 수 있는지 알아봅시다. 위 그림 처럼 만약 노드 1이 t 의 term 에서 리더를 맡고있다고 했을때, 갑자기 노드 1에 네트워크 장애가 나서 노드 2, 노드 3에 접근을 하지 못하는 경우 노드 2, 3은 새로운 리더를 선출할 것입니다. 둘 중 노드 3이 리더로 뽑혔다고 할 때, 여기서 노드 1은 그 과정을 모르기 때문에 본인이 리더라고 생각하고, 노드 1, 노드 3 모두 각자가 리더로 생각되는 상황이 발생하게 됩니다.
이런 이유 때문에, 새로운 리더가 선정되었다고 해도 그 즉시에는 다른 노드가 그 사실을 알지 못하고 있을 수 있기 때문에 확실히 확인하고 넘어가는 과정이 필요합니다.
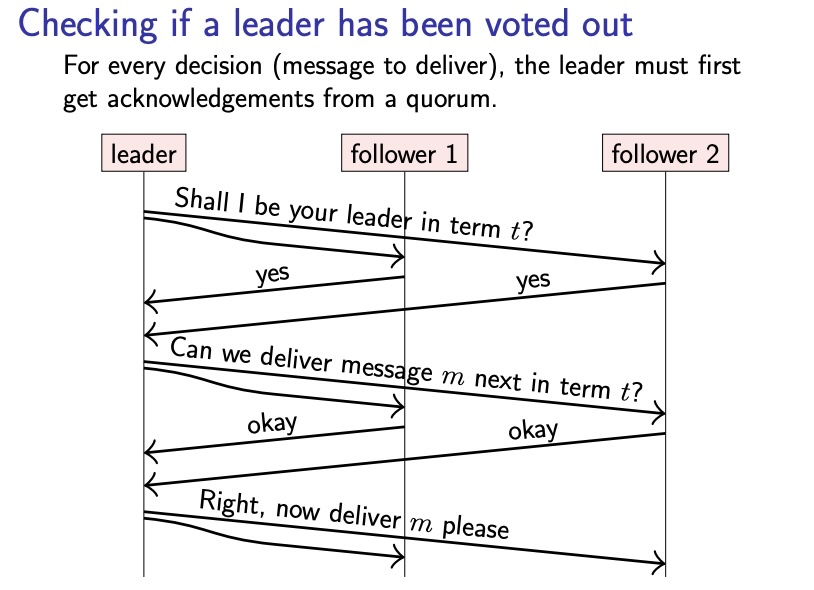
그래서.. 위 그림처럼 TCP 의 3-handshake 마냥 질의와 응답을 통해 실제 리더로써 동작해도 되는지의 검증을 거친 후 동작하게 됩니다.
이후에는 Raft 알고리즘에 대해서 자세하게 살펴보도록 하겠습니다.
'아키텍쳐' 카테고리의 다른 글
| 서비스의 고가용성(HA)를 지키기위해 적용 할 수 있는 방법 들 (1) | 2024.06.30 |
|---|---|
| [강의 정리] Distributed System 6.2: Raft consensus algorithm (..ing..) (1) | 2023.04.12 |
| [강의 정리] Distributed System 5.3: Replication using broadcast (2) | 2023.03.31 |
| [강의 정리] Distributed System 5.2: Quorums (정족수) (0) | 2023.03.31 |
| [강의 정리] Distributed Systems 5: Replication (0) | 2023.03.29 |



댓글