# 강의 영상
정리
이번 4 장에서는 여러 참여 노드들에 메시지를 보내는 방식인 "broadcast protocols(multicast protocols)" 방식에 대해서 알아볼 것입니다. 실 환경에는 여러 broardcast protocol 들이 존재하는데, 이 방식 들은 여러 노드 들에 메시지를 보낸다는 컨셉은 동일하지만 어떤 식으로 메시지를 정렬 할 것인가 에 대한 차이점이 존재합니다. 그리고 우리는 바로 이전 글에서 time 을 기준으로 메시지를 정렬하는 방법에 대해서 살펴보았습니다. 즉, 이번 장에서는 분산 시스템에서 clock 을 통해 메시지를 추적하는 방안에 대해서 조금 더 깊게 파고들어 보겠습니다.
Logical time
clock 을 구분짓는 큰 부분으로 Logical 과 physical 이 있습니다. logical 은 이벤트 단위의 순서를 확인 하는 방식을 말하며, physical 은 실제 초단위로 어느 정도의 시간이 흘렀나를 확인하는 방식을 말합니다. 우리는 이전 장에서 physical clocks를 사용했을 때, 시간 동기화가 깨질 수 있다는 것을 살펴보았습니다. (NTP 로 동기화 하더라도). 하지만 logical clock 은 분산 시스템에서 각 이벤트의 순서를 확인하는데 집중합니다.

logical clocks 에도 크게 두가지 종류가 있습니다. Lamport 와 Vector 가 있는데요, 우선 Lamport 부터 확인해보도록 하겠습니다.
Lamport 알고리즘을 간략하게 표현하면 아래와 같습니다.

Lamport timestamp 는 이벤트가 발생한 횟수를 나타내는 정수형 값입니다. 실제로 physical time 과 관련이 없죠. 각 노드에서는 event 가 발생 할 때마다 이 Lamport timestamp 가 증가하게 됩니다. 그리고 노드에서 메시지를 전송하려 할 때, 이 메시지에 Lamport timestamp 값을 같이 포함하여 보냅니다. 아래 그림 처럼, m1 메시지를 보낼때 현재 timestamp 인 2 를 보내게 되고, B 에서는 m2 를 보낼 때 현재 timetamp 인 4 를 포함해서 보내게 됩니다. 여기서 보는 중요한 특징은, a -> b 대로 이벤트가 일어난 다고 했을 때, a의 Lamport timestamp 는 b 의 Lamport timestamp 보다 무조건 작은 값이라는 것입니다.
즉, 만약 L(e) 를 event 'e' 에 대한 Lamport timestamp 라고 한다면 a -> b 인 경우에 L(a) < L(b) 임을 확신할 수 있지만,
L(a) < L(b) 인 경우에는 역으로 a -> b 이거나 a || b 임을 확신 할 수 있습니다.
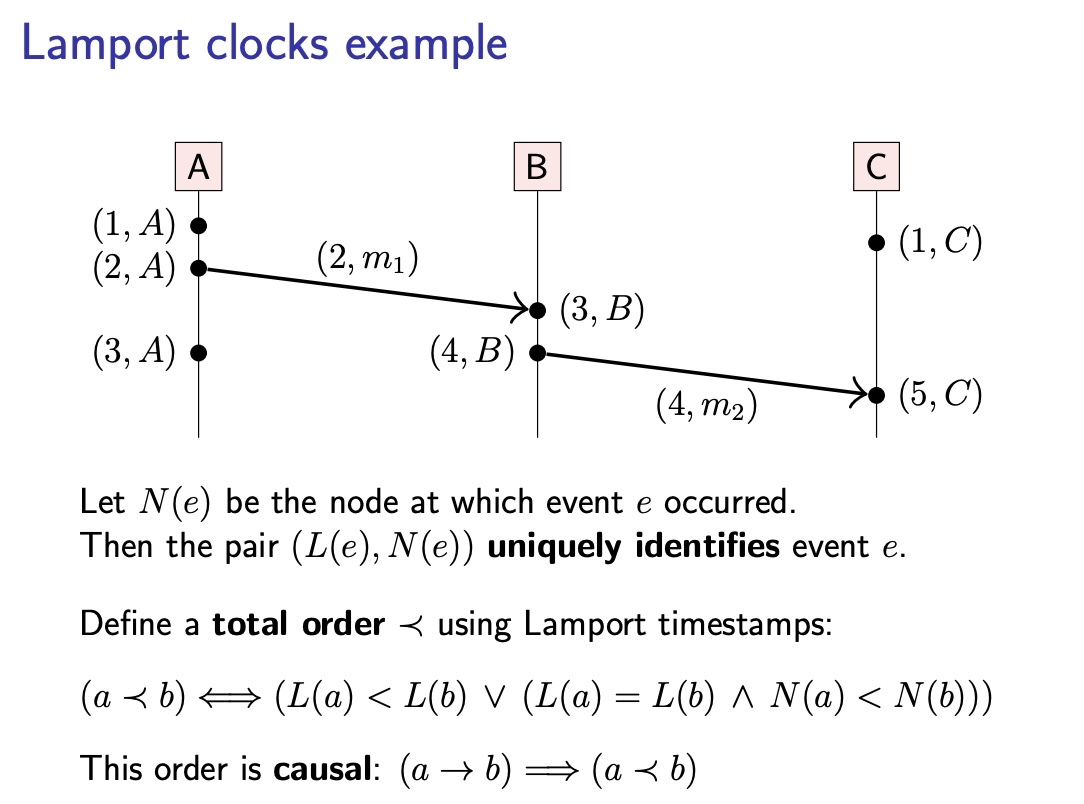
또한, L(e) 값이 같다고 해서 동일한 이벤트 임을 보장 할 수 없습니다. 각 노드에서는 고유의 timstamp 를 진행하고 있기 때문이죠. 여기서 분산 시스템 전반적으로 유니크 함을 확인하기 위해서는 (L(e), N(e)) 쌍을 비교 해야 합니다. 여기서 N(e) 는 'e' event 가 발생한 노드를 나타냅니다.
이전의 "happens-before relation" 의 부분 정렬에 대해서 생각해 보면, 우리는 이 Lamport timestamp 를 이용해서 부분 정렬을 전체 정렬(total order) 로 확장 시킬 수 있습니다.
하지만, 위에서 언급했던 것처럼 결과적인 내용을 보면 두 Lamport timstamp 가 주어졌을 때 이 이벤트들이 인과관계가 있는지 없는지를 판단 하기는 어렵습니다. 다시 말하면, 기존 Lamport timestamp 에서는 L(a) < L(b) 일 때 이 a, b 가 서로 인과 관계가 있는지 즉 a -> b 인지 a || b 인지 확인할 수 없었습니다. 그렇기 때문에 다른 유형의 Logical time 인 "Vector clock" 이 필요합니다.
Vector clock 은 단순 정수형 이었던 Lamport timestamp 와 다르게 배열 형태로 구성되어 있습니다. 만약 n 번째 노드를 vector 에 추가 하게 되면 <N1, N2, . . . , Nn> 로 표현이 될 것이고, vector timestamp 는 <t1, t2, . . . , tn> 로 표현 될 것입니다. 여기서 ti 는 Ni 에 매칭 되는 vector timestamp 입니다. 각 노드는 각자의 고유한 logical timetamp 값을 가지고 있으며, vector 로 표현된 <t1, t2, . . . , tn> 에서 만약 2번째 노드 라면 t2 번째에 timestamp 를 명시하게 됩니다. 즉 ti 는 노드 Ni 에 해당하는 이벤트의 순번을 표현하고 있습니다. vector clock 의 알고리즘은 아래에서 확인 할 수 있습니다.

그리고 위 알고리즘 대로 작동하는 예시에 대해서 아래에서 확인 할 수 있습니다. 아래 예시 중 하나의 timestamp 를 자세히 보면 <2,2,0> 이 나타내는건 A 노드에서 2번의 이벤트가 일어났고, B 노드 에서 2번, C 노드에서는 0번의 이벤트가 일어났다고 해석할 수 있습니다.

그러면, 위 와 같은 방식으로 표기 했을 때 어떻게 인과 관계를 추론해 낼 수 있을까요?
우선 우리는 특정 vector 모든 element 가 다른 vector 보다 작거나 같은 값을 가질 때 이 특정 vector 는 다른 vector 보다 작거나 같다 라고 표현할 수 있습니다. 하지만 최소 하나라도 element 가 크거나 한다면 비교할 수 없는 상태가 됩니다. 예를 들어서 a= <2,2,0> 과 b=<2,2,1> 이 되었다고 하면 a 는 b 보다 작거나 같다 라고 표현할 수 있지만, c=<0,0,1> 이 되어서 a 랑 비교 하게 되면 a, c 는 비교 불가능한 상태로 남아 있게 됩니다. 즉 a 는 b 보다 작은 벡터라고 한다면 a -> b 의 관계 임을 유추해 볼 수 있습니다. 즉 벡터의 대소를 구분하여 아래와 같이 표현 될 수 있습니다.
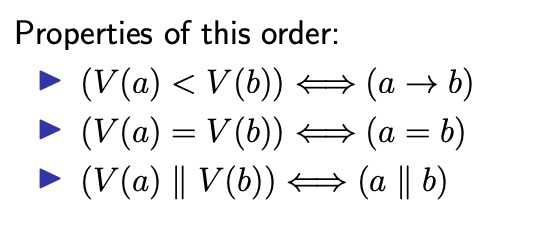
우리는 지금 까지 이렇게 Lamport timestamp 와 Vector timestamp 를 살펴 보았습니다. 하나는 전체 순서를 파악 할 수 있고, 하나는 부분 순서에 대한 인과 관계를 파악할 수 있었습니다.
'아키텍쳐' 카테고리의 다른 글
| [강의 정리] Distributed System 5.2: Quorums (정족수) (0) | 2023.03.31 |
|---|---|
| [강의 정리] Distributed Systems 5: Replication (0) | 2023.03.29 |
| [강의 정리] Distributed System 3.3: Causality and happens-before (0) | 2023.03.21 |
| [강의 정리] Distributed System 3.2: Clock synchronisation and monotonic clocks (0) | 2023.03.16 |
| [강의 정리] Distributed System 2.4: Fault tolerance and high availability (0) | 2023.03.15 |




댓글